

เครื่องมือ Data Science
เครื่องมือ Data Science คุณเคยสงสัยหรือไม่ว่า กระบวนการสำคัญเบื้องหลังของความก้าวหน้า ของเทคโนโลยีต่าง ๆ เช่นการเรียนรู้ของเครื่อง และความเป็นจริงนั้น คืออะไร? คำตอบคือ Data Science
หรือวิทยาศาสตร์ข้อมูล เป็นสาขาวิชาที่รวมสถิติ สารสนเทศ การวิเคราะห์ข้อมูล และวิธีการที่เกี่ยวข้องต่าง ๆ เพื่อทำความเข้าใจรูปแบบที่ซับซ้อน ที่ซ่อนอยู่ภายในข้อมูลที่มีโครงสร้าง หรือไม่มีโครงสร้าง
ใช้ทฤษฎี และเทคนิคที่มาจากหลากหลายสาขาในบริบทของวิทยาการสารสนเทศ วิทยาการคอมพิวเตอร์ และความรู้โดเมน
วันนี้ มีเครื่องมือขั้นสูงมากมายบนอินเทอร์เน็ต เพื่อดึงความรู้จากข้อมูลประเภทต่าง ๆ อย่างไรก็ตาม ไม่ใช่ทั้งหมดที่ควรค่าแก่การลอง
ในบทความนี้ เราได้รวบรวมเครื่องมือวิทยาศาสตร์ข้อมูลที่ดีที่สุด ที่นักวิจัย และนักวิเคราะห์ธุรกิจสามารถใช้เพื่อสร้างข้อมูลเชิงลึกอันมีค่า
ก่อนที่เราจะเริ่ม เราต้องการชี้แจงว่า รายการนี้มีเฉพาะเครื่องมือ Data Science ไม่ใช่ภาษาโปรแกรม หรือสคริปต์สำหรับการนำ Data Science ไปใช้งาน ดังนี้
1. Apache Hadoop
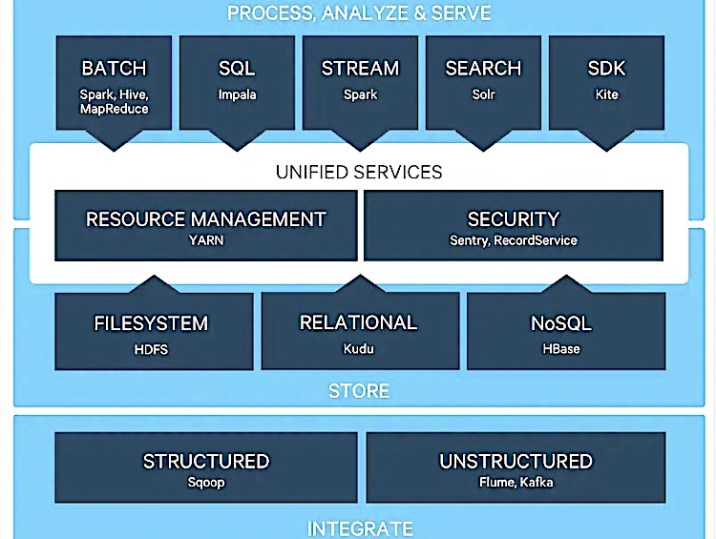
Hadoopคือระบบนิเวศของยูทิลิตี้โอเพนซอร์ซที่เปลี่ยนแปลงวิธีการจัดเก็บ ประมวลผล และวิเคราะห์ข้อมูลของธุรกิจโดยพื้นฐาน ต่างจากแพลตฟอร์มทั่วไป
ซึ่งช่วยให้เวิร์กโหลดการวิเคราะห์ประเภทต่าง ๆ ทำงานบนข้อมูลเดียวกันได้ ในเวลาเดียวกันในขนาดใหญ่บนฮาร์ดแวร์มาตรฐานอุตสาหกรรม
Hadoop กระจายชุดข้อมูลขนาดใหญ่และงานวิเคราะห์ข้ามโหนดต่างๆ ในคลัสเตอร์การประมวลผล โดยแปลงเป็นเวิร์กโหลดขนาดเล็กลงที่สามารถดำเนินการแบบขนานได้
มันสามารถจัดการทั้งข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง และขยายจากเครื่องเดียวไปยังอุปกรณ์หลายพันเครื่อง
โดยรวมแล้ว Hadoop รวมเอารูปแบบข้อมูลที่เกิดขึ้นใหม่ (เช่น ความรู้สึกของโซเชียลมีเดียและข้อมูลการคลิกสตรีม) และช่วยให้นักวิเคราะห์ทำการตัดสินใจ ที่ขับเคลื่อนด้วยข้อมูลแบบเรียลไทม์ได้ดียิ่งขึ้น
2. RapidMiner
RapidMinerพัฒนาบนโมเดลโอเพ่นคอร์รองรับขั้นตอนทั้งหมด ของวิธีการเรียนรู้ของเครื่อง รวมถึงการจัดเตรียมข้อมูล การสร้างภาพผลลัพธ์ การตรวจสอบแบบจำลอง และการเพิ่มประสิทธิภาพ
นอกเหนือจากชุดข้อมูลของตัวเองแล้ว RapidMiner ยังมีตัวเลือกมากมายในการตั้งค่าฐานข้อมูลในระบบคลาวด์สำหรับการจัดเก็บข้อมูลจำนวนมหาศาล
คุณสามารถจัดเก็บและโหลดข้อมูลจากแพลตฟอร์มต่าง ๆ เช่น NoSQL, Hadoop, RDBMS และอื่นๆ
งานทั่วไป เช่น การประมวลผลข้อมูลล่วงหน้า การแสดงภาพ และการล้างข้อมูลสามารถทำได้ผ่านตัวเลือกการลากและวางโดยไม่ต้องเขียนโค้ดแม้แต่บรรทัดเดียว
ไลบรารีของ RapidMiner (ซึ่งมีฟังก์ชันและอัลกอริธึมมากกว่า 1,500 รายการ) ช่วยให้มั่นใจว่าโมเดลที่ดีที่สุดสำหรับกรณีการใช้งานใด ๆ
นอกจากนี้ ยังมาพร้อมกับเทมเพลตที่ออกแบบไว้ล่วงหน้าซึ่งสามารถใช้ในกรณีการใช้งานทั่วไป เช่น การตรวจจับการฉ้อโกง การบำรุงรักษาเชิงคาดการณ์ และการเลิกราของลูกค้า
แพลตฟอร์มนี้ใช้อย่างแพร่หลายในการพัฒนาซอฟต์แวร์ธุรกิจและเชิงพาณิชย์ เช่นเดียวกับการสร้างต้นแบบอย่างรวดเร็ว การศึกษา การฝึกอบรม และการวิจัย
นักวิเคราะห์มากกว่า 700,000 คนใช้ RapidMiner เพื่อเพิ่มรายได้ ลดต้นทุนการดำเนินงาน และหลีกเลี่ยงความเสี่ยง
3. สถิติ IBM SPSS
SPSS Statistics เป็นแพลตฟอร์มซอฟต์แวร์ ทางสถิติ ที่ทรงพลังที่ช่วยให้คุณได้รับประโยชน์สูงสุดจากข้อมูลอันมีค่าที่ข้อมูลของคุณมอบให้
ได้รับการออกแบบมาเพื่อแก้ปัญหาทางธุรกิจและการวิจัยผ่านการวิเคราะห์โดยละเอียด การทดสอบสมมติฐาน และการวิเคราะห์เชิงคาดการณ์
SPSS สามารถอ่านและเขียนข้อมูลจากสเปรดชีต ฐานข้อมูล ไฟล์ข้อความ ASCII และแพ็คเกจสถิติอื่น ๆ สามารถอ่านและเขียนตารางฐานข้อมูลเชิงสัมพันธ์ภายนอกผ่าน SQL และ ODBC
คุณสมบัติหลักส่วนใหญ่ของ SPSS สามารถเข้าถึงได้ผ่านเมนูแบบเลื่อนลง คุณสามารถใช้ภาษาไวยากรณ์คำสั่ง 4GL เพื่อลดความซับซ้อนของงานที่ทำซ้ำ ๆ และจัดการการจัดการ และวิเคราะห์ข้อมูลที่ซับซ้อน
นักวิจัยตลาด ผู้ขุดข้อมูล รัฐบาล และบริษัทสำรวจใช้แพลตฟอร์มนี้อย่างกว้างขวาง เพื่อทำความเข้าใจข้อมูล วิเคราะห์แนวโน้ม ตรวจสอบสมมติฐาน และให้ข้อสรุปที่ถูกต้อง

วิทยาศาสตร์ข้อมูล, AI และ ML ต่างกันอย่างไร
Data Science เป็นสาขาวิชากว้าง ๆ ที่เกี่ยวข้องกับการประมวลผลล่วงหน้า การวิเคราะห์ และการแสดงภาพข้อมูลที่มีโครงสร้างและไม่มีโครงสร้าง
ข้อมูลเชิงลึกที่ได้รับจากข้อมูลจะถูกนำไปใช้กับโดเมนแอปพลิเคชันที่หลากหลาย
ปัญญาประดิษฐ์หมายถึงการสอนเครื่องให้เลียนแบบพฤติกรรมมนุษย์ในทางใดทางหนึ่ง เป้าหมายของการวิจัย AI
รวมถึงการแทนความรู้ การวางแผน การเรียนรู้ การใช้เหตุผล การประมวลผลภาษาธรรมชาติ การรับรู้ และความสามารถในการจัดการกับวัตถุ
แมชชีนเลิร์นนิงเป็นส่วนย่อยของ AI ที่เน้นวิธีการใช้ข้อมูล และอัลกอริทึมเพื่อเลียนแบบวิธีที่มนุษย์เรียนรู้ ยิ่งโมเดล ML ได้รับข้อมูลมากขึ้น (หรือที่เรียกว่าข้อมูลการฝึก) ยิ่งทำให้คาดการณ์ได้แม่นยำยิ่งขึ้นโดยไม่ต้องตั้งโปรแกรมไว้อย่างชัดเจน
วิทยาศาสตร์ข้อมูลมีขั้นตอนอย่างไร
วิทยาศาสตร์ข้อมูลเกี่ยวข้องกับการทำซ้ำหกขั้นตอน
- แผน : กำหนดโครงการ และผลลัพธ์โดยประมาณ
- สร้างแบบจำลองข้อมูล : ใช้เครื่องมือวิทยาศาสตร์ข้อมูลที่เหมาะสม เพื่อสร้างแบบจำลองการเรียนรู้ของเครื่อง
- ประเมิน : ใช้เมตริกการประเมินและการแสดงภาพ เพื่อวัดประสิทธิภาพของแบบจำลองเทียบกับข้อมูลใหม่
- อธิบาย (อย่างง่าย) กลไกภายในของแบบจำลองแมชชีนเลิร์นนิง
- ปรับใช้โมเดลที่ได้รับการฝึกอบรมมาอย่างดีในสภาพแวดล้อมที่ปลอดภัย และปรับขนาดได้
- ตรวจสอบแบบจำลอง เพื่อให้แน่ใจว่าทำงานอย่างถูกต้อง
Data Science ช่วยธุรกิจได้อย่างไร
วิทยาศาสตร์ข้อมูล มีบทบาทสำคัญในการวิเคราะห์สุขภาพของธุรกิจ โดยจะดึงข้อมูลที่มีค่าจากข้อมูลดิบ และคาดการณ์อัตราความสำเร็จของผลิตภัณฑ์และบริการของบริษัท
นอกจากนี้ ยังช่วยในการระบุความไร้ประสิทธิภาพในกระบวนการผลิต การกำหนดเป้าหมายผู้ชมที่เหมาะสม และการสรรหา ผู้มีความสามารถที่เหมาะสมสำหรับองค์กร
บางภาคส่วนใช้วิทยาศาสตร์ข้อมูล เพื่อเพิ่มความปลอดภัยให้กับธุรกิจ และปกป้องข้อมูลที่ละเอียดอ่อน ตัวอย่างเช่น ธนาคารใช้อัลกอริธึมการเรียนรู้ของเครื่องเพื่อตรวจจับการฉ้อโกงตามกิจกรรมทางการเงิน
ตามปกติของลูกค้า อัลกอริธึมเหล่านี้ ได้รับการพิสูจน์แล้วว่ามีประสิทธิภาพ และแม่นยำในการระบุการฉ้อโกงมากกว่าการตรวจสอบด้วยตนเอง
ตามรายงานของ GlobalNewswire ตลาดแพลตฟอร์มวิทยาศาสตร์ข้อมูลทั่วโลก จะสูงถึง 224 พันล้านดอลลาร์ ภายในปี 2569 ซึ่งเติบโตที่ CAGR ที่ 31 เปอร์เซ็นต์
Credit